字符串匹配相对来说是一个很常见的问题,无论是在工程中还是在笔试和面试中。
一般来说,字符串匹配的输入有一个原字符串和一个子串,要求返回子串在原字符串中首次出现的位置。即,c++标准库中的find函数。
本文以leetcode的第28题实现strStr()为例,总结几种常见的字符串匹配算法。
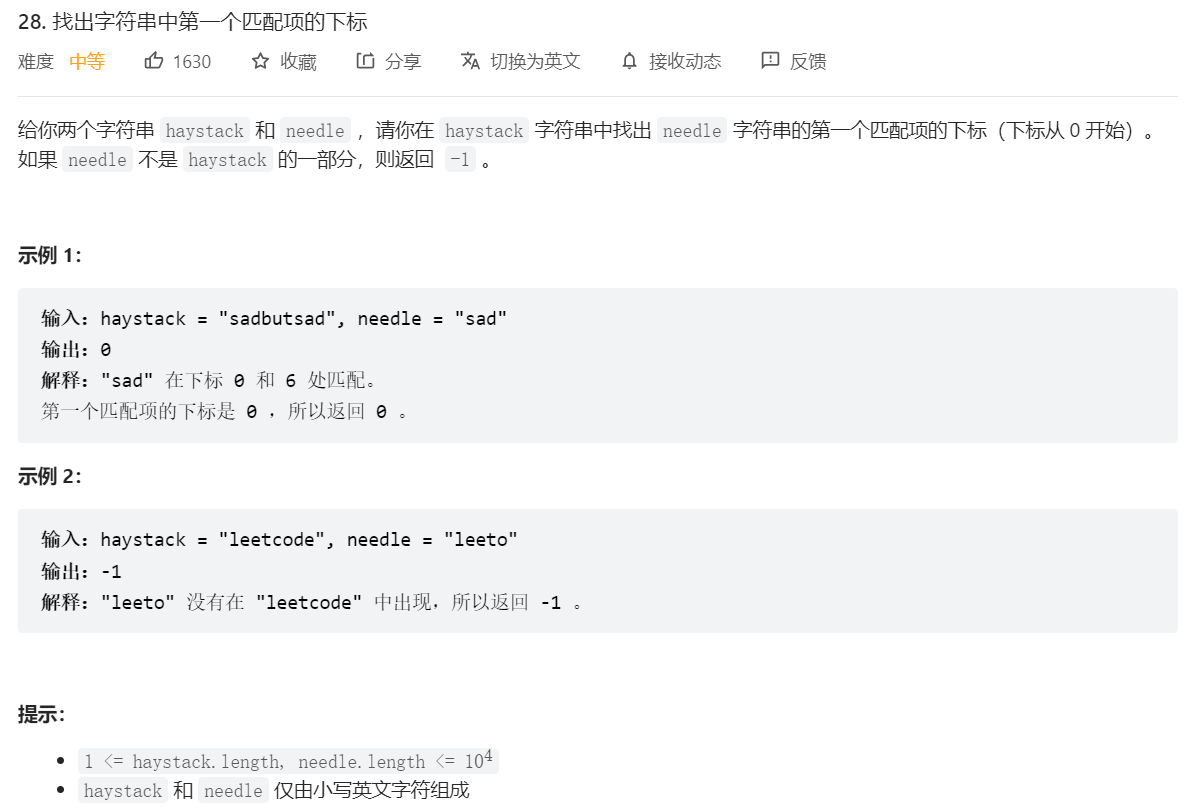
1. 暴力匹配
这种方法是最容易想到的。
将原字符串和子串的左端对齐,逐一比较。若第一个字母匹配上,则继续向后滑动,比较下一个字母。若不匹配,则将原字符串的左端向后滑动一位,子串的左端对齐,继续比较。
class Solution {
public:
int strStr(string haystack, string needle) {
int left = 0, right = 0;
while(right < haystack.size()) {
if(haystack[left] == needle[0]) { // 第一个字母匹配上
bool flag = true;
for(int i = 0; i < needle.size(); i++, right++) {
if(haystack[right] != needle[i]) {
flag = false;
break;
}
}
if(flag) return left;
}
// 没有匹配上,继续向后移动
left++;
right = left;
}
return -1;
}
};2. RABIN KARP 字符匹配算法
Rabin-Krap算法的核心思想是hash。本质上,是对暴力搜索的一种优化。在暴力搜索时,每次原字符串的左端和子串的左端匹配上,我们都需要匹配剩下的所有字符。而在Rabin-Krap算法中,我们只需要比较子串的hash值和原字符串的hash值是否相等即可。这种算法实际上被用于论文查重的工作中。
根据labuladong的算法笔记,我们先从一个简单的例子开始理解。
假设我们有一个字符串形式的数字,将之转化为int型。
int str2int(string s) {
int res = 0;
for(auto p : s) {
res = 10 * res + (p - '0');
}
return res;
}举这个例子的目的是为了说明两个操作:
- 如何在数字的最低位添加数字?将数字整体左移(十进制数乘十),左移后的数字加上要添加的数字。
- 如何在数字的最高位删除数字?获取此时数字的最高位数字,用最高位数字乘以10的此时数字的位数次方,在用原来的数字减去这个数字。
为了理解上述两个操作在Rabin-Krap算法中的应用,我们先来看一道简单的题,leetcode187.重复的DNA序列。
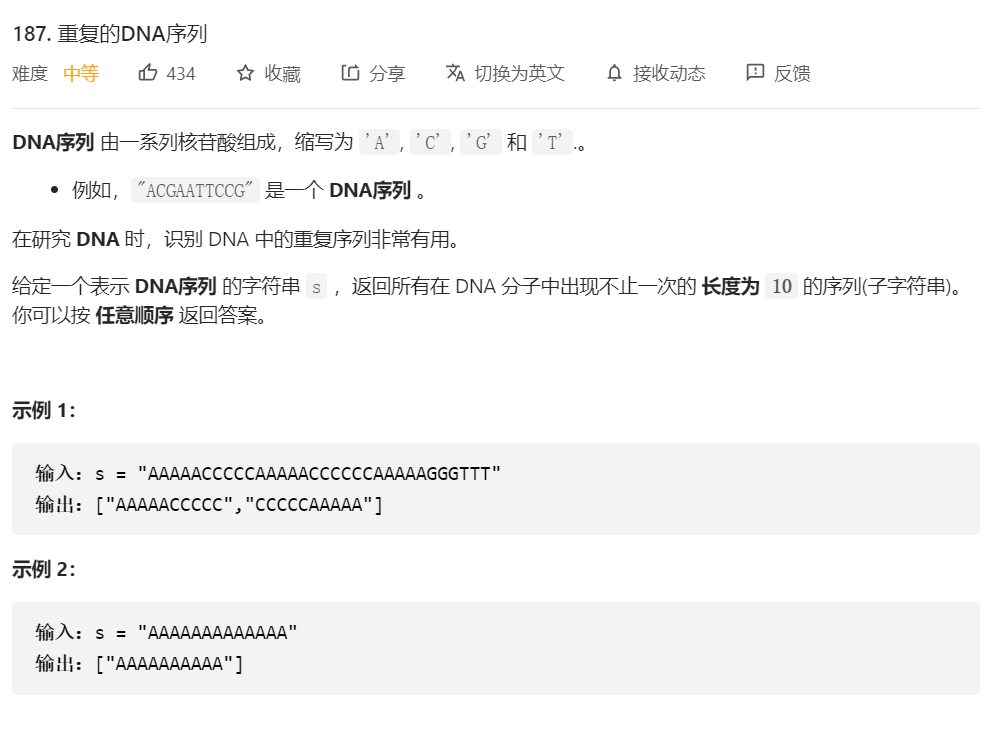
直观上来看,这题的解法很简单,使用一个set来存储已经出现过的DNA序列,如果当前的DNA序列已经在set中出现过,则将其加入结果集中。
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
set<string> res;
unordered_set<string> st;
for(int i = 0; i + 10 <= s.size(); i++) {
string tmp = s.substr(i, 10);
if(st.count(tmp)) res.insert(tmp);
else st.insert(tmp);
}
return vector<string>(res.begin(), res.end());
}
};这题和我们上边说的有什么关系?在上述的解法中,我们使用了substr函数。其实,可以使用滑动窗口的思想,结合上述的两种操作来避免每一次都要调用substr函数。
class Solution {
public:
int char2int(char c) {
switch(c) {
case 'A': return 0;
case 'C': return 1;
case 'G': return 2;
case 'T': return 3;
}
return -1;
}
vector<string> findRepeatedDnaSequences(string s) {
set<string> res;
unordered_set<int> st;
int left = 0, right = 0;
long long hash = 0;
while(right < s.size()) {
hash = hash * 10 + (char2int(s[right]));
if(right - left + 1 == 10) {
if(st.count(hash)) res.insert(s.substr(left, 10));
else st.insert(hash);
hash -= (char2int(s[left])) * pow(10, 9);
left++;
}
right++;
}
return vector<string>(res.begin(), res.end());
}
};其实到了这里,已经很像Rabin-Krap算法了。只是,现在的字符串只有四种字符,而实际上,ASCII码有256种字符,所以应该是将字符串hash到256进制的数进行处理。其他的逻辑都是相同的,这里的重点在于怎么处理256进制数,计算字符串的hash值,对hash值进行上述的两种操作。下边展示了一种实现Rabin-krap算法的伪代码。
// 待匹配的文本
string txt;
// 模式串
string pat;
int l = pat.size();
int r = 256;
int rl = int(power(r, l - 1));
int window_hash = 0;
// 计算pat的hash值
int pat_hash = 0;
for(int i = 0; i < pat.size(); i++) {
pat_hash = r * pat_hash + int(pat[i]);
}
// 滑动窗口
int left = 0, right = 0;
while(right < txt.size()) {
window_hash = r * window_hash + int(txt[right]);
right++;
if(right - left == l) {
if(pat_hash == window_hash) {
return left;
}
else {
window_hash = window_hash - txt[left] * rl;
left--;
}
}
}
return -1;我们使用了十进制数来作为hash值,但是一个十位的256进制数就需要一个25位的十进制数才能表示,这样,只要pat的位数稍微多一些,很容易就会超出long甚至是long long类型的上界。
因此,我们使用取余的方法进行处理,但是这会导致新的问题,即出现hash冲突。解决hash冲突常用的方法有拉链法和线性探查法。但是这里的解决方法是在出现hash冲突时,使用暴力匹配的方法将原字符串和pat进行比对。由于hash冲突不常出现,因此,暴力匹配并不太影响算法的时间复杂度。
此时,我们已经可以写出完整的Rabin-krap算法。
class Solution {
public:
// 使用Rabin-krap
int strStr(string haystack, string needle) {
int l = needle.size();
int r = 256;
long q = 1658598167;
long rl = 1;
// 计算rl的值
for(int i = 1; i <= l - 1; i++) {
rl = (rl * r) % q;
}
// 计算needle的hash值
long needle_hash = 0;
long window_hash = 0;
for(int i = 0; i < needle.size(); i++) {
needle_hash = (r * needle_hash + int(needle[i])) % q;
}
// 滑动窗口
int left = 0, right = 0;
while(right < haystack.size()) {
window_hash = ((r * window_hash) % q + int(haystack[right])) % q;
right++;
if(right - left == l) {
if(needle_hash == window_hash) {
// 检查是否真的匹配
bool flag = true;
for(int i = 0; i < l; i++) {
if(haystack[left + i] != needle[i]) {
flag = false;
break;
}
}
if(flag) return left;
}
// 移除最左侧字符
window_hash = ((window_hash - int(haystack[left]) * rl) % q + q) % q;
left++;
}
}
return -1;
}
};在上边给出的代码中,q应该为尽可能大的素数,可以降低哈希冲突的概率。具体的证明由数学推导给出。
3. KMP算法
KMP 算法(Knuth-Morris-Pratt 算法)是一个著名的字符串匹配算法。
在开始之前,我们约定pat为模式串,长度为m,txt为待匹配的文本,长度为n。

