Gated PixelCNN
论文中提出的模型结合了PixelRNN和PixelCNN的优点。
主体结构还是PixelCNN,因为PixelCNN使用卷积运算,可以节省运算时间和运算资源。
相比于PixelCNN,PixelRNN的优点是使用了门控单元,且没有感受野盲区。分别针对这两点对PixelCNN进行了针对性的改进。
Gated activation
首先,使用门激活函数代替PixelCNN中的线性激活函数。有助于建模更加复杂的interactions。门激活函数的数学表达式如下所示:
式中的参数分别表示:
$\sigma$:sigmoid函数
$k$:卷积的层数
$\odot$:逐元素点乘
*:卷积操作
$W_{k, f}$:第k层的卷积核
$W_{k, g}$:第k层的卷积核
解决Blind spot
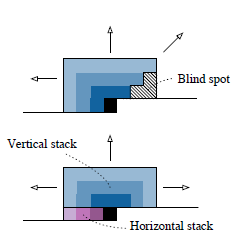
Gated PixelCNN的输入被分为了两个部分,一部分是vertical,一部分是horizontal。vertical包含了现在行之上的所有行,而horizontal包含了现在行之前的所有的像素点。
github上已经有了完整的验证代码。
在每一层结束之后,都将这两个stack的输出结合起来。
两者的结合方式如图所示,使用简单的卷积。
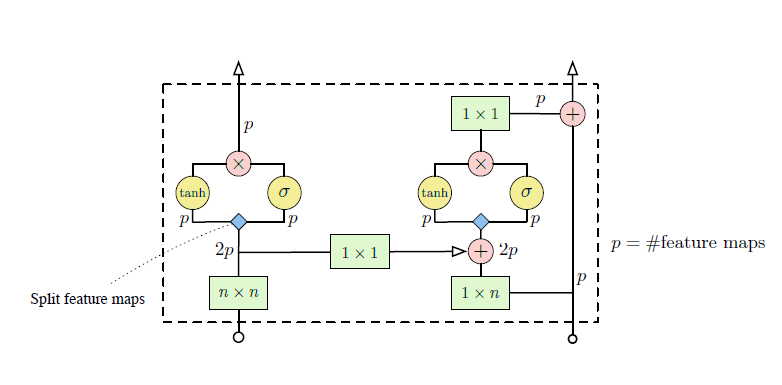
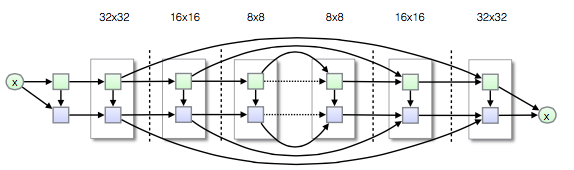
Conditional PixelCNN
Gated PixelCNN在给定一些先验条件的情况下也可以成为一个条件图片生成器。
原始版的PixelCNN建模的对象为:
在加入先验条件$h$之后,建模的对象变成了:
此时,Gated激活函数的表达式也需要变化:
式中:
$\mathrm{s}$: h在频域上的表示,$\mathrm{s} = m(\mathrm{h})$
$V_{k,f}$: $1\times 1$的卷积
PixelSnail
为了保证网络的设计可以满足能够轻松的推断出序列的前部分的要求,可能有以下几种做法。
- 传统的RNN,LSTM和GRU
- 因果卷积
- 自注意力机制
因果卷积可以在有限的上下文中提供高带宽的访问方式,attention机制可以在很大的上下文中应用causal attention,使网络学习到挑出聚集到的哪些信息,以及如何更好地表现这些信息。snail(simple neural attentive meta-learner)便是由两个卷积和attention交错而成。
为了在二维的图片上保证卷积的因果性,只能使用masked convolution(最原始的pixelcnn的做法)或者shift-based convlution(上文中介绍的gated-pixelcnn中将masked conv kernel分块的做法)。
但是,卷积操作只能提取到局部的信息,为了保证能够使用到全局的信息,必须进行卷积层的堆叠。在这个过程中,通常使用到的操作时dilated convolution和strided convolution,通过膨胀系数的选取实现感受野的指数级扩增。
尽管使用了dilated convolution和strided convolution,但是边缘处的像素信息依然是受限的—由于每次卷积仅能提取到有限的上下文中的信息,这些信息往往要通过一系列的中继。
大多数pixelCNN中都使用了raster scan的方式,即从左到右,再从上到下扫描。这样扫描大多数的上下文都被浪费在了距离要推断的点比较远的部分,比如说右上角的点。因此本文使用了zigzag ordering。
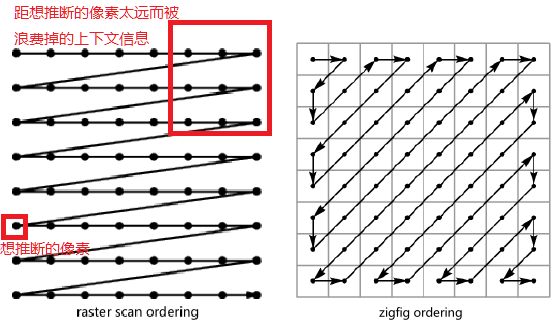
但是,使用这种扫描的顺序会导致blind spot的出现,为了解决这个问题,提出了pixelSNAIL—使用了更大更灵活的感受野。
pixelSNAIL的主要做法是引入attention模块。

